Local AI vs. The Cloud: Why the Linux Kernel is Moving Bug Detection On-Prem
The Linux kernel community is currently facing a unique paradox. On one hand, AI-driven bug reports are flooding in at record speeds. On the other, many of these reports are "slop"—low-quality, automated noise that creates more work for maintainers than it solves.
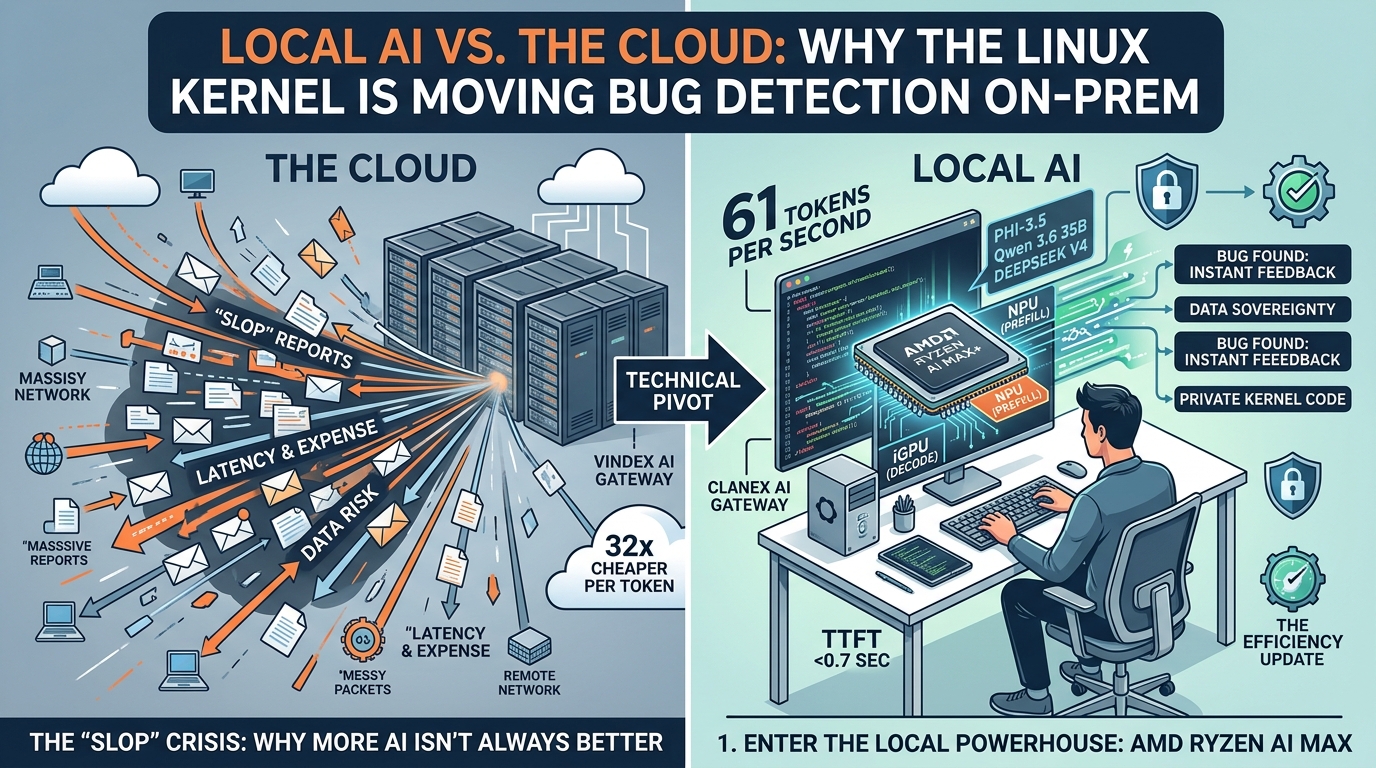
The current strategy of relying on massive, cloud-based models for bug detection is hitting a wall. These systems are expensive, introduce significant network latency, and—most importantly—often lack the deep, local context of the specific hardware they are testing. As highlighted by the emergence of Clanker-T1000, the community is starting to realize that for bug detection to be useful, it needs to be fast, private, and local.
The shift away from the cloud isn't just a philosophical choice; it’s a hardware-driven reality. The AMD Ryzen AI Max+ 395 has emerged as the gold standard for this "Local First" approach.
Unlike traditional chips, the Ryzen AI Max utilizes a hybrid architecture:
The NPU (Neural Processing Unit): Handles the initial "prefill" phase of a prompt with incredible efficiency.
The iGPU: Takes over for the "decode" phase, pushing performance to a staggering 61 tokens per second on models like Phi-3.5.
This means a developer can run a sophisticated LLM on a Framework desktop and get near-instant feedback on a code patch without ever sending a single byte of proprietary kernel code to an external server.
In the world of kernel development, every millisecond matters. Cloud-based models, even the fastest ones, are beholden to the speed of the light through fiber optics.
The Cloud Reality: High latency, "Time to First Token" (TTFT) that can feel sluggish, and massive monthly bills.
The Local Reality: The Ryzen AI Max delivers a TTFT of under 0.7 seconds.
When your AI is sitting inches away from your CPU, the feedback loop for debugging becomes instantaneous. You aren't "waiting for a report"; you're having a real-time conversation with your codebase.
We’ve spent the last year obsessed with "who has the biggest model." But as the recent launch of DeepSeek V4 shows, the industry is pivoting toward efficiency.
While cloud giants like NVIDIA are pushing tokens at massive scales (up to 3,500 tokens per second on Blackwell clusters), that power comes with a price tag that only a handful of corporations can afford. DeepSeek V4-Flash-Max has proven that you can achieve frontier-level reasoning (competing with GPT-5.4-Cyber) at a fraction of the cost—specifically 32x cheaper per token.
This efficiency makes "Local AI" commercially viable for the first time. Why pay for a cloud subscription when a one-time hardware investment in a Ryzen-powered workstation can do the same work for "free" for the next three years?
Perhaps the most critical advantage of the Vindex AI Gateway approach is security. Kernel bugs are, by definition, security vulnerabilities. Sending an unpatched, high-severity bug to a cloud provider for "analysis" is a massive risk.
By running Clanker-T1000 or similar models locally, developers ensure:
Data Sovereignty: The bug stays on the machine until the patch is ready.
No "Leaking" via Training: Your proprietary or sensitive code isn't accidentally sucked into the next version of a public model's training set.
The trade-off? Local AI requires a "systems thinking" mindset. You can't just hit an API; you have to manage model weights (like the Qwen 3.6 35B), configure GPU offloading, and ensure your Linux drivers are up to date. It’s more "engineering" and less "prompting."
But for those who make the jump, the rewards are clear: a faster development cycle, zero monthly fees, and a level of privacy that the cloud simply can't promise.
The "Efficiency Revolution" is here. We are moving from a world where we operate software to a world where software—running locally on our own silicon—works on our behalf. Whether you are a Linux maintainer or a SaaS founder, the choice is becoming clear:
Do you want to rent your intelligence from the cloud, or do you want to own it on your desk?
At Vindex AI, we’re choosing to own it.
Sources
- 1.The New Linux Kernel AI Bot Uncovering Bugs Is A Local LLM On Framework Desktop + AMD Ryzen AI Max - Phoronix
- 2.NVIDIA Beats Everyone To DeepSeek V4 With Day-0 Blackwell Support, Pushing 3,500 Tokens Per Second On 1.6T Models - Wccftech
- 3.DeepSeek V4 Shows That The Next AI Race Is About Efficiency - Forbes
Stay updated
Get our latest technical articles and product updates delivered to your inbox.